This post is a clean version of an investigation I made 2 years ago (May 2022) as part of a feature I was developing with a hard requirement for implementing a cache. The main reason was to prevent traffic burst and because the service will get data from a downstream service that is vended daily. In this post, we will explore what caching is, when to use it, and some strategies to take into account while considering caching in your software.

Table of contents#
Open Table of contents
What is caching?#
In computing, a cache is a high-speed data storage layer that stores a subset of data, typically transient in nature. So that future requests for that data are served up faster than is possible by accessing the data’s primary storage location. Caching allows you to efficiently reuse previously retrieved or computed data[2].
Caching aims to improve the performance and scalability of a system. It does this by temporarily copying frequently accessed data to fast storage that is located close to the application. As a result, it improves response times for client applications by serving data more quickly.
When to use caching?#
The basic reason to use a cache is, when you have a pool of data, you might need to retrieve very frequently and the frequency at which it changes is low then you are just going to access the same data repeatedly over a period of time, you should consider using a cache.
Several factors[3] can lead a software developer to consider adding a cache layer to their system. Some of them are listed below:
- When dependency starts throttling or otherwise be unable to keep up with the expected load;
- It is helpful to consider caching when encounter uneven request patterns that lead to hot-key/hot partition throttling;
- Data from a dependency is a good candidate for caching if such a cache has a good cache hit (see cache hit) ratio across requests. Thus, results of calls to the dependency can be used across multiple requests or operations;
- How tolerant a team’s service and its client are to eventual consistency. Cached date necessarily grows inconsistent with the source overtime, so caching can only be successful if both service and its clients compensate accordingly.
When not to use caching?#
When requests typically require a unique query to the dependent service with unique-per request results, then a cache would have a negligible hit rate and the cache does not good.
How to use caching?#
Before deep diving into how to use caching, let’s define some terms.
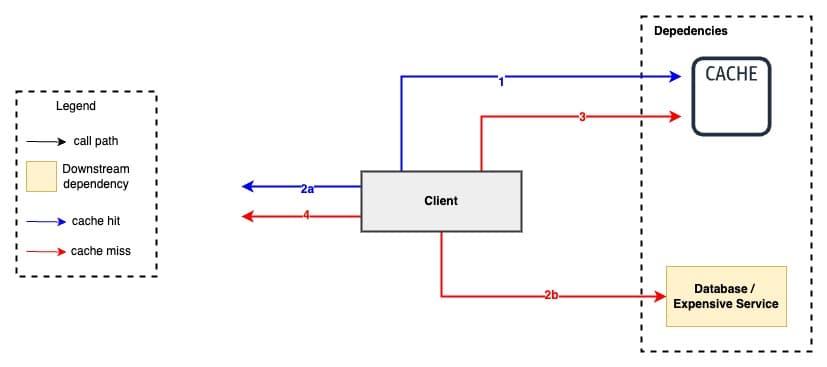
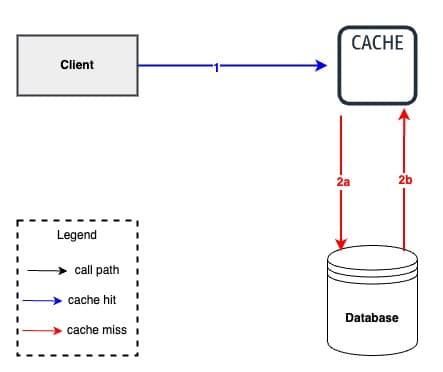
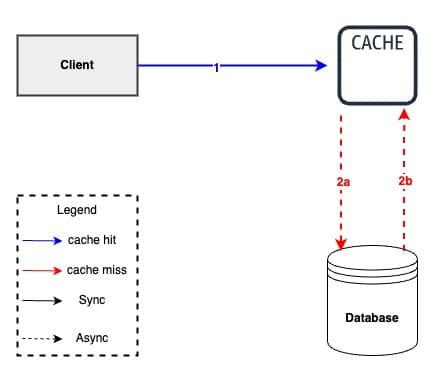
Cache hit#
A cache hit is a state in which data requested for processing by a component or application is found in the cache memory. It is a faster means of delivering data to the processor, as the cache already contains the requested data.
A cache hit serves data more quickly, as the data can be retrieved by reading the cache memory. The cache hit also can be in disk caches where the requested data is stored and accessed at the first query.
Cache miss#
Cache Miss is a state where the data requested for processing by a component or application is not found in the cache memory. It causes execution delays by requiring the program or application to fetch the data from other cache levels or the main memory.
A cache miss occurs either because the data was never placed in the cache, or because the data was removed (“evicted”) from the cache by either the caching system itself or an external application that specifically made that eviction request. Eviction by the caching system itself occurs when space needs to be freed up to add new data to the cache, or if the time-to-live policy on the data expired.
How to apply caching#
Caching is applicable to a wide variety of use cases, but fully exploiting caching requires some planning. When deciding whether to cache a piece of data, consider the following questions.
- Is it safe to use a cached value? The same piece of data can have different consistency requirements in different contexts.
- Is caching effective for that data? Some applications generate access patterns that are suitable for caching.
- Is the data structured well for caching? Simply caching a database record can often be enough to offer significant performance advantages. However, other times, data is best cached in a format that combines multiple records. Because caches are simple key-value stores, you might also need to cache a data record in multiple different formats, so you can access it by different attributes in the record.
Caching Strategies#
Read Strategies#
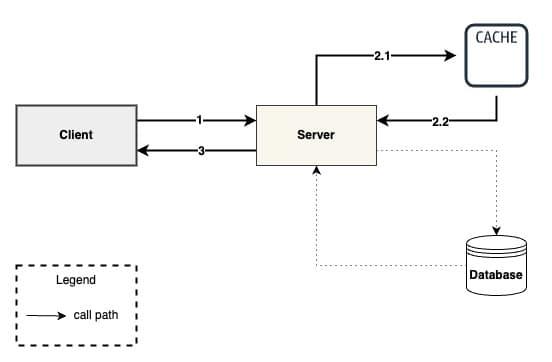
Lazy Loading or Cache aside#
Lazy Loading or Cache aside is a caching strategy that loads data into the cache only when necessary. If application needs data for some key x, search in the cache first. If data is present, return the data, otherwise, retrieve the data from the data source, put it into cache and then return.
This approach has some advantages.
- It does not load or hold all the data together, it is on demand. Suitable for cases when you know that your application might not need to cache all data from the data source in a particular category.
- The cache only contains objects that the application actually requests, which helps keep the size manageable. New objects are only added to the cache as needed. You can then manage your cache memory passively, by simply letting the engine you are using evict the least-accessed keys as your cache fills up, which it does by default.
- As new cache nodes come online, in instance when your application scales up, the lazy loading will automatically add objects to the new cache nodes when the application first requests them.
- Cache expiration is easily handled by simply deleting the cached object. A new object will be fetched from the database the next time it is requested.
There are some disadvantages you can consider before choosing this approach.
- When the cached data set is static. If the data fit into the available cache space, prime the cache with the data on startup and apply a policy to prevent the data from expiring.
- For caching session state information in a web application hosted in a web farm. In this environment, you should avoid introducing dependencies based on client-server affinity.
- Stale data might become an issue. If data changes in the database and the cache key is not expired yet, it will throw stale data to the application.
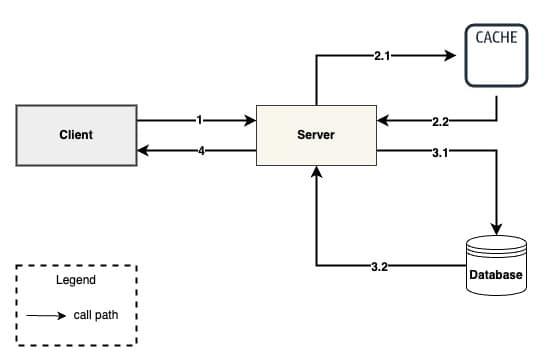
Read through#
The read-through is a caching strategy where the cache is positioned as an intermediary between the application and the underlying data source (like a database). When an application needs data, it first checks the cache. If the data is already in the cache (a cache miss), it’s returned immediately, offering low-latency access. If the data isn’t in the cache (a cache miss), the cache itself takes on the responsibility of fetching the data from the database, storing it, and then returning it to the application. In essence, the cache “reads through” to the database when necessary, ensuring the application always has seamless access to the data, whether it’s cached or not.
This approach has some advantages.
- Data is added to the cache only when needed. This “lazy loading” approach ensures that only actively requested data is cached.
- The application always interacts with the cache as its primary data source, offering a consistent interface whether the data is readily available or needs to be fetched.
- Once data is cached, subsequent reads are fast, improving overall performance, especially for frequently accessed information.
Like the other strategies, this approach has some disadvantages.
- The first time data is requested (and on any cache miss), there’s a delay while the cache retrieves it from the database. This can result in higher response times for that initial request.
- Managing a read-through cache can get tricky, especially if the data retrieval logic is complex or if there are multiple sources for the data.
- Since the cache automatically stores data, there’s a potential for serving outdated information if the underlying data changes and the cache aren’t refreshed or invalidated in time.
- The application heavily relies on the cache being available. If the cache goes down, performance can degrade as the application reverts to direct database queries.
Write strategies#
Write-through#
The write-through or inline cache adds data or updates data in the cache whenever data is written to the database.

This approach has certain advantages over lazy loading.
- It avoids cache misses, which can help the application perform better and feel snappier.
- It shifts any application delay to the user updating data, which maps better to user expectations. By contrast, a series of cache misses can give a user the impression that your app is just slow.
- It simplifies cache expiration. The cache is always up-to-date.
- It is suitable for read heavy systems which can’t much tolerate staleness.
- It is also a uniform API model for clients. Caching can be added, removed, or tweaked without any changes to the client logic.
However, write-through caching also has some disadvantages.
- The cache can be filled with unnecessary objects that are not being accessed. Not only could this consume extra memory, but unused items can evict more useful items out of the cache.
- It can result in lots of cache churn if certain records are updated repeatedly.
- When the cache node fails, those objects will no longer be in the cache. You need some way to repopulate the cache of missing objects.
- It is a write penalty system. Every write operation does two network operations.
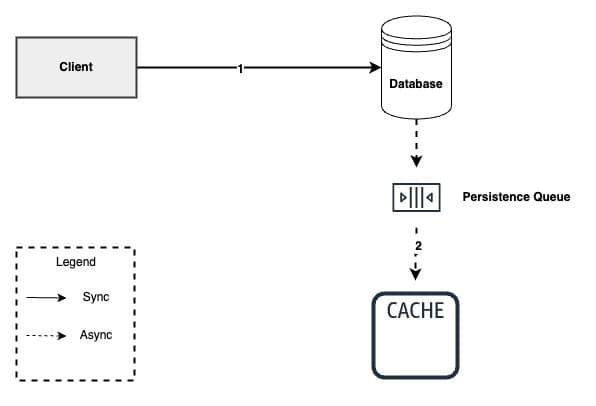
Write behind#
The Write behind caching writes data directly to the caching system. Then after a certain configured interval, then written data is asynchronously synced to the underlying data source. Here the caching service has to maintain a queue of write operations so that they can be synced in order of insertion.

This approach has certain advantages over the others.
- Since the application writes only to the caching service, it does not need to wait till data is written to the underlying data source. Read and write both happen on the caching side. Thus, it improves performance.
- The application is insulated from database failure. If a database fails, queued items can be retried or re-queued.
- Suitable for a high read and write throughput system.
As the others approach, it has some disadvantages too. The main one is the eventual consistency between a database and caching system. So any direct operation on a database or joining operation may use stale data.
Refresh Ahead#
The refresh ahead caching is a technique in which the cached data is refreshed before it gets expired.
What it does is it essentially refreshed the cache at a configured interval just before the next possible cache access,
although it might take some time due to network latency to refresh the data, and meanwhile a few thousand read operations
already might happen in a very highly read heavy system in just a duration of few milliseconds.
The main advantages of this approach are:
- It is useful when a large number of users are using the same cache keys. Since the data is refreshed periodically and frequently, staleness of data is not a permanent problem.
- Reduced latency than another technique like lazy loading.
One of the disadvantages of this method is that it is probably a little hard to implement since service takes extra pressure to refresh all the keys as, and they are accessed. But in a read heavy environment, it is worth it.
Write around#
Adding Time-to-live (TTL)#
TTL is an integer value that specifies the number of seconds until the keys expires. When an application attempts to read an expired key, it is treated as though the key is not found.
Cache expiration#
Cache expiration can get really complex quickly. Unfortunately, there is no panacea for this issue. But there are a few strategies that you can use:
- Always apply TTL to all of your cache keys, except those you are updating by write-through caching.
- For rapidly changing data such as comments, leaderboards, or activity streams, rather than adding write-through caching or complex expiration logic, we could just set a short TTL of a few seconds.
- A newer pattern, Russian doll caching[4], has come out of work done by Ruby on Rails team. In this pattern, nested records are managed with their own cache keys, and then the top-level resource is a collection of those keys.
- When in doubt, just delete a cache key if you are not sure whether it is affected by a given database update or not. Your lazy caching foundation will refresh the key when needed. In the meantime, your database will be no worse off than it was without caching.
Eviction Policy#
Evictions occur when memory is over filled or greater than the maximum memory setting in the cache, resulting into the engine to select keys to evict to manage its memory. The keys that are chosen are based on the eviction policy that is selected.
- Least Recently Used (LRU): In this strategy, the algorithm takes care of discarding the least recently used items first. For example, a service that gets the same response again and again at least for some time window, can safely evicted cached data not used very recently or sort of cold data.
- Least Frequently Used (LFU): The characteristics of this approach involve the system keeping track of the number of times a block is referenced in memory. When the cache is full and requires more room, the system will purge the item with the lowest reference frequency.
- Most Recently Used (MRU): In contrast to LRU, MRU discards the most recently used items first. MRU algorithms are most useful in situations where the older an item is, the more likely it is to be accessed.
- First In, First Out (FIFO): As the name suggested it, this policy behaves in the same way as a FIFO queue. The cache evicts the blocks in the order they were added, without any regard to how often or how many times they were accessed before.
- Adaptive Replacement Cache (ARC): is a page replacement algorithm[5] with a better performance than LRU. The algorithm consists of constantly balancing between LRU and LFU to improve the combined result.
- Adaptive Climb (AC): Uses recent hit/miss to adjust the jump where in climb any hit switches the position one slot to the top and in LRU hit switches the position of the hit to the top.
A good strategy in selecting an appropriate eviction policy is to consider the data stored in your cluster and the outcome of keys being evicted. Generally, LRU based policies are more common for basic caching use-cases, but depending on your objectives, you may want to leverage a TTL or Random based eviction policy if that better suits your requirements.
The thundering herd or the cache stampede#
The thundering herd effect is what happens when many application processes simultaneously request a cache key, get a cache miss, and then each hits the same database query in parallel. The more expensive this query is, the bigger impact it has on the database. If the query involved is a top 10 query that requires ranking a large dataset, the impact can be a significant hit.
Caching technologies#
There are two big families of caching technologies: local caches and external caches.
Local caches#
On-box caches, commonly implemented in process memory, are relatively quick and easy to implement and can provide significant improvements with minimal work. Local caches come with no additional operational overhead, so they are fairly low-risk to integrate into an existing service.
In-Memory caches come with some downsides among which we have:
- Cache coherence problem: Data inconsistency from server to server across its fleet;
- Downstream load is proportional to the service’s fleet size, so as the number of servers grows, it still may be possible to overwhelm dependent services;
- In-memory caches are susceptible to cold start issues. These issues occur where a new server launches with a completely empty cache, which could cause a burst of requests to dependent service as it fills its cache.
External caches#
An external cache stores cached data in a separate fleet. Cache coherence issue is reduced because the external cache holds the value used by all servers in the fleet. Overall load on downstream services is reduced compared to in-memory caches and is not proportional to fleet size. Cold start issues during events like deployments are not present since the external cache remains populated throughout the deployment. Finally, external caches provide more available storage space than in-memory caches, reducing occurrences of cache eviction due to space constraints.
External caches come also with its downsides.
- It increases overall system complexity and operational load
- The availability characteristics of the cache fleet will be different from the dependent service it is acting as a cache for.
Cache classification#
Caching solution can be classified per layer.
| Layer | Use case | Technologies | Solutions |
|---|---|---|---|
| Client-side | Accelerate retrieval of web content from websites | HTTP cache headers, browsers | Browser specific |
| DNS | Domain to IP resolution | DNS Servers | Route 53 |
| Web | Accelerate retrieval of web content from web/app servers. Manage web sessions | HTTP cache Headers, CDNs, Reverse Proxies, Web Accelerators, Key/Value stores | Cloudfront, Elasticache (Redis or Memcached) |
| App | Accelerate application performance and data access | Key/Value data stores, Local caches | Elasticache (Redis or Memcached), MemoryDB for redis |
| Database | Reduce latency associated with database query requests. | Database buffers, Key/Value data stores | Elasticache (Redis or Memcached), MemoryDB for redis |
Conclusion#
Caching is a powerful tool that can dramatically improve the performance and scalability of your applications when used correctly. By storing frequently accessed data closer to the application, it reduces latency and offloads pressure from downstream services. However, implementing a cache requires careful consideration of factors like data consistency, eviction strategies, and cache expiration. The choice of caching strategy—whether it’s lazy loading, read-through, write-through, or others—depends on your specific use case and access patterns.
It’s crucial to strike a balance between performance gains and the complexities that caching introduces. From the thundering herd problem to stale data risks, each caching solution comes with its own trade-offs. Understanding these nuances and planning accordingly will ensure that your caching implementation provides the maximum benefit without introducing new challenges.
Appendix#
- Cache-cache, “hide and seek” in English is the name of the game we all played during our childhood in which at least two players conceal themselves in a set environment, to be found by one or more seekers. The use of the term “cache-cache” in the title is purely for pun purposes.
- Caching challenges and strategies
- Caching challenges and strategies
- The performance impact of “Russian doll” caching
- Page replacement algorithm
- This blog post image is generated using Dall-E 2. The prompt use to generate the image is the following: An abstract scene of children playing hide and seek. The image has a blend of cinematographic and drawing-like elements, with vibrant yet soft colors. The children are in a playful, imaginative environment, with exaggerated shadows and whimsical shapes. Some children are hiding behind stylized trees and surreal objects while others are counting with eyes closed. The atmosphere is dreamy, with motion blur to suggest movement and excitement, blending realism with artistic, hand-drawn textures.